3D Printing in Dental Industry

Since the introduction of the first 3D printing technology in 1986, additive manufacturing has been showing impressive growth in the constantly increasing range of industries adopting the cutting-edge technologies. Dentistry is among those taking all the benefits of 3D printing most willingly and rapidly.

Credit: placervilledentistry.com
This is Top 3D Shop, and in this article, we are going to discuss different aspects of digital dentistry and find out which 3D printing solutions are the best fit for this application.
Biocompatible dental 3D printing for labs and clinics

Credit: dentalhospitalthailand.com
The traditional workflow in dentistry implies the cooperation of two parties involved in the process — dental clinics on the one side and prosthesis laboratories on the other, the interaction between the two requiring quite a lot of time and logistics. Since every patient has a unique dentition, dental labs mostly use manual production methods which are usually slow and assume the work of highly skilled dental technicians, still leaving a lot of room for probable imperfections in the final result. The use of 3D printing provides wide opportunities for low-cost mass customization, saving time and ensuring extremely high precision of printed models. A wide range of dedicated biocompatible materials with various properties allows for the creation of orthodontic models, crowns and bridges, surgical guides, aligners, retainers, splints, dentures, and other dental products that perfectly match the patient’s anatomy.
Applications of 3D printing in dental industry
Aligners

Credit: china-ortholab.com
Aligner production is an example of using 3D printing as a bridge to traditional manufacturing methods. First the dentist takes the impression of the patient’s mouth by means of intraoral scanning with further converting the scanned data to a CAD model, which is then edited to specify the stages of desired teeth shifting. When this is done, the model for each stage is printed, usually employing SLA technology. After that each printed model is placed into a thermoforming machine where a clear aligner is wrapped around it creating the patient-specific set of aligners.
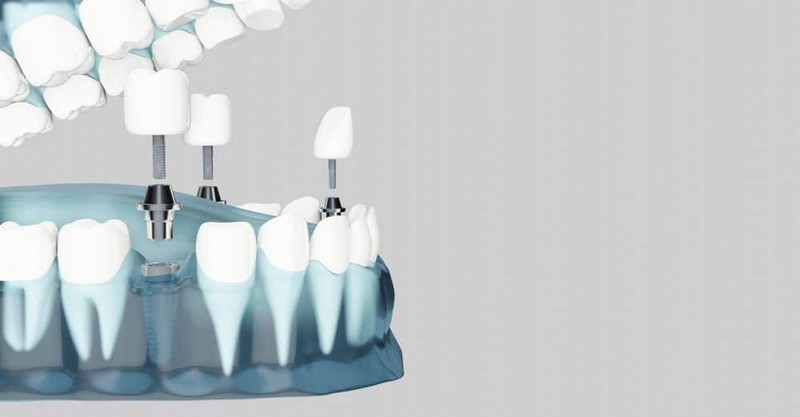
Surgical guides
Credit: creativedentistry.ca
Surgical guides are used in medicine, dentistry in particular, to assist the surgical procedures. In dentistry surgical guides are of great help in implantation as they ensure the precise placing and fitting of the implant. The guides are placed directly over the patient's teeth and then removed during or after the surgery when no longer needed. Surgical guides not only increase the accuracy of the procedure, but also make it faster and less invasive thus shortening the recovery time. Different manufacturers offer special surgical guide resins to ensure the best printing results.
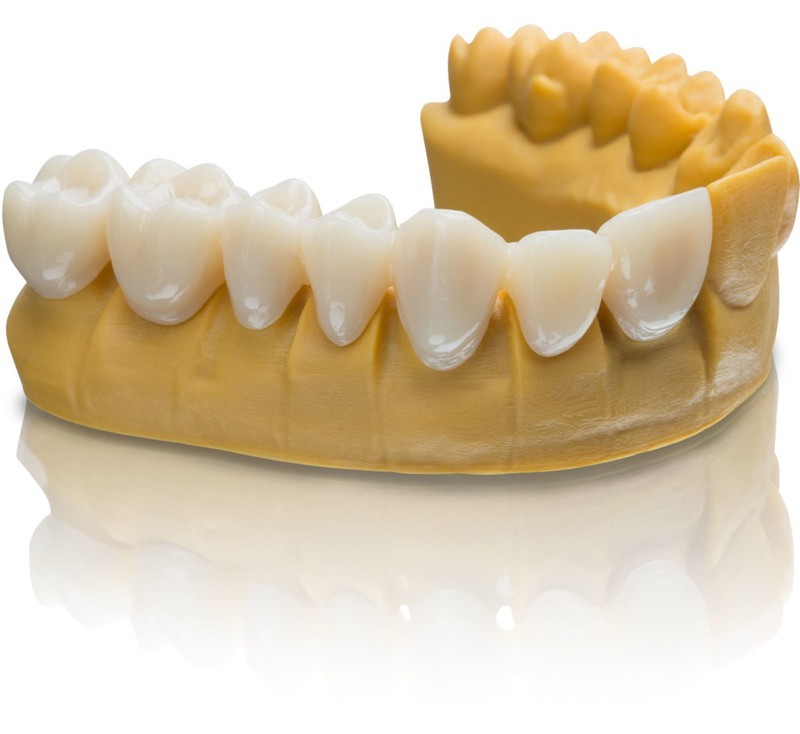
Crowns
Credit: dentalimplantxperts.com
3D printed dental crowns are becoming more widespread with the development of new biocompatible materials. First additive manufacturing was used only as a bridge to investment casting process helping create accurate casting patterns. Now there are a variety of materials, from special permanent crown resins, like Formlabs Digital Dentures Resin, to various metal alloys, that allow printing high-quality permanent crowns taking all the advantages 3D printing provides.
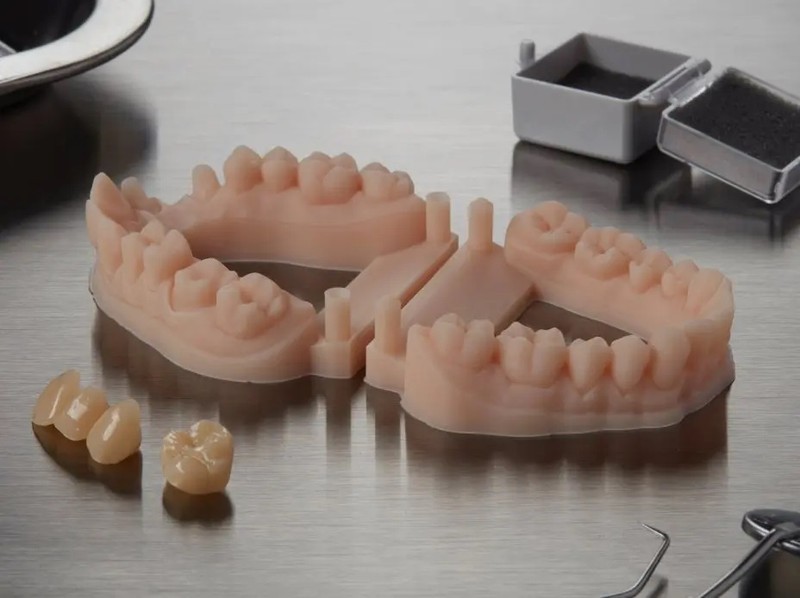
Dental models
Credit: dental.formlabs.com
Dental full arch or crown and bridge models with removable dies help dentists while planning denture restoration. Dental models are printed based on the digital impression of the patient's mouth so they are indispensable when it comes to checking fixed prosthetics that will be later used in a patient's treatment. Special materials, like Formlabs Dental Model Resin allow for precise models with matte smooth surface and a high level of detail.
How are dental models 3D printed?
The process of 3D printing in dentistry always starts with the dentist taking a digital impression of a patient’s mouth with an intraoral or desktop scanner. The obtained data is converted to a CAD model which can be saved and then used as a basis for creating dental print models when needed. The digital model is sliced using appropriate software and sent to the printer. Once printed, dental parts usually require some post-processing steps depending on the technology and type of material used.
Does dental 3D printing require special training?
The process of dental 3D printing is mainly automated and generally requires less special skills than dental technician’s work. Still, certain training is required, especially for those not familiar with additive manufacturing technologies in general. 3D printing equipment and material manufacturers usually offer training programs and support for their customers. In fact, digital dentistry allows for chair-side creation of some patient-specific dental products, while more complex parts have to be printed in dental labs by skilled professionals.
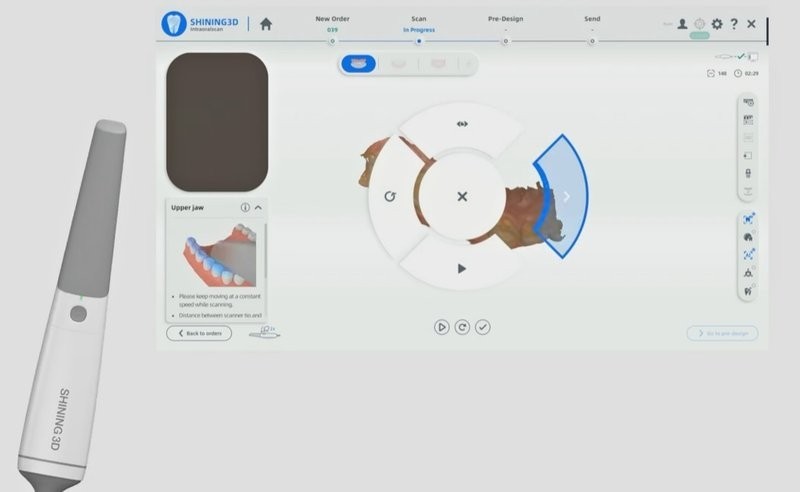
How to get digital models for a 3D printer
As mentioned, a dental 3D scanner (for example, Shining 3D Aoralscan 3) is used to capture the patient’s dental anatomy and take a digital impression of their teeth and gums. This digital impression is converted to a CAD file that is edited to create a digital model of the specific dental product, for example, a crown, depending on the particular case and treatment plan.
How to print dental custom trays
In traditional dentistry trays are used to get a patient's teeth impression, usually with plaster. The implementation of 3D technologies offers much more convenient and precise digital impressions made with an intraoral scanner. Yet impression trays are still widely used in dentistry either by those who prefer conventional methods, or in cases when digital scanning is impossible for some reason. The use of standard trays has always been a compromise as they can not guarantee the necessary precision which a custom-made 3D printed tray provides. The process of printing is the same as with other dental products, and the final result ensures getting highly precise dental products in a shorter time. Different manufacturers offer special resins for impression trays production.
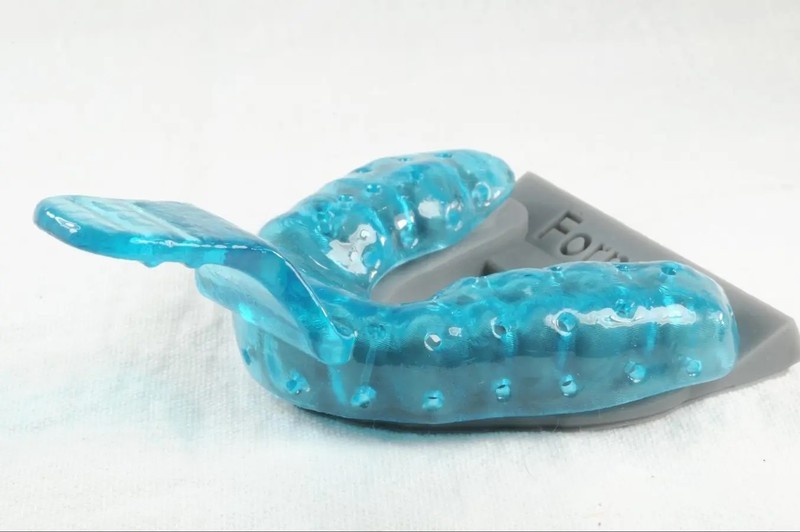
Credit: dental.formlabs.com
Criteria for top dental 3D printers
Precision
Print precision is one of the key points to be considered when choosing a dental 3D printer. If you are going to print not only educational models just to show your patients the treatment process in detail (in that case almost any desktop 3D printer will do), but working dental products, then you should look for a high resolution device, as even subtle discrepancy can lead to a completely unsatisfying result.
Speed
Speed is always of great importance when it comes to business. High print speeds are helpful, whether we speak about dental labs or in case of chair-side printing in dental clinics, where rapid printing helps minimize the number of a patient’s appointments with the dentist.
Biocompatible materials support
It’s by far the main feature the printer should possess to be called dental. All dental products that come in contact with the patient’s mouth or skin should be certified biocompatible in your area, so it’s highly recommended to check the material compatibility list while choosing a dental 3D printer.
Dental printing materials
For today, the most popular technology for dental 3D printing is vat photopolymerization, which includes SLA, DLP and LCD-based processes, all of them using liquid resins that are cured by a light source. Hence the choice of special dental resins in the market is really vast. All dental resins are biocompatible and can be used for printing temporary or permanent dental parts with required properties.

Credit: megadas.com
Metal 3D printers are becoming more and more widespread in dentistry as they work with different metal and metal alloy powders, for example, titanium or cobalt chromium, traditionally used for fabrication of crowns, dentures, and stents. DMLS printers are capable of producing durable extremely precise models in a short time.
Another popular technology for dental 3D printing is material jetting that prints with liquid materials — plastics or polymers — which are cured by UV light. The technology boasts the exceptional accuracy of the printed models, but the printers utilizing this technology are usually bulky and expensive.
As for FDM printing, despite its popularity in a lot of other industries, it has not been widely used in dentistry, as FDM machines usually demonstrate lower accuracy than the other technologies mentioned above. However, new FDM 3D printer models show much higher resolution, accuracy, and dimensional stability, compared to their predecessors, and now dental industry can take advantage of all the benefits of FDM technology.
Best dental 3D printers 2022
Resin 3D printers
Phrozen Sonic 4K 2022

The Phrozen Sonic 4K 2022 is a desktop LCD-based resin 3D printer equipped with a monochrome 4K (3840 x 2160) LCD screen with the resolution of 772 PPI and the lifespan of 2000 hours. Due to the upgraded dedicated ParaLED Matrix 3.0 technology, the device can print layers at a minimum height of 10 microns. Together with the XY resolution of only 35 microns, it allows creating incredibly accurate precise models with a perfectly smooth surface finish. The Sonic 4K 2022 is a reliable and fast 3D printer capable of building a single layer in just two seconds. It can be operated via PC or a built-in 5" touchscreen and boasts wide connectivity options including Ethernet, USB, and Wi-Fi interfaces. The Phrozen Sonic 4K 2022 is designed to meet all the dental printing requirements. Apart from common for the Phrozen 3D printers ChiToBox slicer compatibility, the Sonic 4K 2022 comes with the proprietary Phrozen Dental Synergy Slicer targeted specifically at dental applications.
Credit: @bellwoodlab / Instagram
Pros
- High resolution and accuracy
- Fast print speed
- Sturdy aluminum construction
- Wide connectivity options
- 5" operating touchscreen
Cons
- The build volume is not very large
Phrozen Sonic XL 4K 2022

The Phrozen Sonic XL 4K 2022 is a professional desktop resin 3D printer designed specifically for the dental industry. The model is a larger version of the Phrozen Sonic 4K 2022 with a more spacious build volume of 200 x 125 x 200 mm. This allows printing fairly large parts or multiple dental models in one go for efficient time saving. All other printer specs are similar to the previous model, with the only difference in the XY resolution of 52 microns, compared to 35 microns of the Sonic 4K 2022, due to the larger build volume of the Sonic XL 4K. Despite this, the device is capable of producing astonishingly detailed precise parts with a flawlessly smooth surface finish at a high speed of 2 mm per layer. The printer is compatible with ChiToBox and comes with the designated Phrozen Dental Synergy Slicer. The Phrozen Sonic XL 4K can be successfully used not only for dental applications, but in jewelry fabrication and any other industry where the quality of the parts is of paramount importance.
Credit: @ALICEADMD / Twitter
Pros
- Large build volume
- Fast print speed
- High print quality
- Open material system
- Wide connectivity options
Cons
- The XY resolution is a bit lower compared to the Sonic 4K 2022
Uniz Slash 2

The Uniz Slash 2 is a professional desktop LCD 3D printer with a 8.9" 4K LCD screen. The device boasts an amazing print speed of up to 200 mm/h ensuring extremely high time-efficiency of the printing process. The minimum layer height of 10 microns allows for highly detailed accurate models with flawless look and feel. With a sizable build volume of 192 x 120 x 200 mm you can print either large models or small runs of smaller parts at a time. The printer is equipped with an effective heat management system and a proprietary liquid cooling mechanism. All these features make the Uniz Slash 2 an indispensable tool for dentistry, jewelry, or any other industry with strict part quality requirements.
Credit: @coutelas_v / Instagram
Pros
- Incredibly high speed
- Automatic bed leveling
- High print quality
- Durable resin tank
- Cloud-based services
Cons
- No control screen
Uniz NBEE

The Uniz NBEE is a resin LCD-based 3D printer designed specially for the dental industry. The NBEE features extremely high print speed, being able to produce six dental models in 5 minutes. The printer’s build volume is 192 x 120 x 180 mm. With the minimum layer height of 25 microns, the device prints aligners, removable dies, surgical guides, crowns, bridges, and other dental appliances with exceptional quality. The NBEE can print either with a wide range of special Uniz photosensitive dental resins or with third-party materials.

Credit: uniz.com
Pros
- Extremely high speed
- High print quality
- Wide range of compatible dental resins
Cons
- High price
Formlabs Form 3B+

Credit: dental.formlabs.com
The Formlabs Form 3B+ is based on proprietary LFS (Low Force Stereolithography) technology that is aimed at improving the surface finish of the prints. The Form 3B+ is designed for digital dentistry and can print with minimum layer thickness of 25 microns. The build volume of the printer is 145 x 145 x 185 mm. The device can come alone or with post-processing equipment, including the Form Wash and Form Cure machines. Formlabs offers a wide range of biocompatible resins for different dental appliances (for example, Formlabs Dental LT Clear Resin).

Credit: dental.formlabs.com
Pros
- High print quality
- Wide range of biocompatible resins
- Can be a part of a complete solution
Cons
- Compatible only with proprietary materials
- Lower print speed, compared to LCD models
Nexa3D NXE400

The NXE400 is an industrial resin 3D printer based on proprietary Lubricant Sublayer Photo-curing (LSPc) technology. Due to this technology, the NXE400 is by far one of the fastest resin 3D printers in the market. The machine features a large build volume of 274 x 155 x 400 mm. The print quality the NXE400 is capable of is incredibly high. The NXE400 can be regarded as a reliable 3D printer for a dental lab, as now it supports all biocompatible photopolymer dental resins by Keystone Industries. Apart from that, the NXE400 is compatible with a wide range of other resins, including xPeek, xABS, and xFlex.
Credit: 3dprint.com
Pros
- Extremely high print speed
- High-quality prints with smooth surface finish
- Large build volume
- Wide range of compatible materials
- Dental biocompatible resins support
Cons
- Price can be too high for small companies
FDM 3D printers
Raise3D E2

The Raise3D E2 is an industrial desktop FDM 3D printer featuring the Independent Dual Extrusion System (IDEX) which opens up versatile printing opportunities, from dual-material and dual-color printing to using mirror and duplication modes that allow you to double the production volume. The E2 can print with the maximum nozzle temperature of 300 °C and is compatible with a wide range of filaments, such as PLA, ABS, HIPS, PC, TPU, TPE, Nylon, PETG, ASA, PP, PVA, glass and carbon fiber filled composites, and others. Featuring the auto bed leveling function and a flexible removable heated build plate, the E2 provides perfect first layer adhesion for high-quality accurate printing. The minimum layer height of 20 microns makes for detailed accurate parts with the quality perfectly suitable for printing dental models.
Credit: @priamond.de / Instagram
Pros
- IDEX system
- Auto bed leveling function
- Wide range of compatible materials
- Enclosed chamber with a HEPA filter
- Minimum layer height of 20 microns
- Flexible removable build plate
Cons
- Auto bed leveling can take pretty much time
Creality CR-5 Pro High-temp Version

The Creality CR-5 Pro High-Temp version industrial-grade FDM 3D printer sports a fully-enclosed impressively large build chamber of 300 x 225 x 380 mm. The extruder is equipped with a 0.4 mm nozzle with the maximum temperature of 300 °C and a cooling fan that helps prevent stringing and warping issues. The CR-5 Pro High-temp is compatible with a wide range of filaments, including high-temp materials, such as PLA, TPU, and ABS. Proper first layer adhesion is provided by the high-quality carbon glass heated print bed. A bunch of advanced features, such as auto bed leveling, filament run-out sensor, or print resume function make for consistent reliable printing experience.

Credit: Just Vlad / YouTube
Pros
- Large build volume
- Wide range of compatible materials, including high-temp filaments
- Carbon glass heated print bed
- Auto bed leveling function
- Filament runout sensor
- Print resume function
Cons
- 100 microns minimum layer height
Metal 3D printers
Farsoon FS121M

The Farsoon FS121M is an MLS (metal laser sintering) printer that can perform as a reliable and efficient device for a number of industries, dentistry being one of them. The FS121M sports a large build volume, which is a cylinder of ⌀ 120 x h 100 mm, and a high build speed, allowing for the production of up to 160 dental crowns in 3 hours. The device is equipped with a single 200W fiber laser, used in the Flight series printers. The Farsoon FS121M is a fully open system, providing compatibility with a great number of proprietary and third-party metal powders, including 316L, 17-4PH, Maraging Steel Grade 300, HX, Cu, CuSn10, CoCrMoW, and CoCrMo.

Pros
- Large build volume and compact footprint
- High print quality
- Fast print speed
- Use of more powerful and durable fiber laser
- Open system
BLT-A160D

The BLT-A160D is an industrial-grade SLM metal 3D printer designed specifically for the dental industry. The machine can print with Titanium and Cobalt Chromium alloys that are widely used in dentistry for producing high-quality stents and dentures. The A160D features a build volume of 160 x 160 x 100 mm and can print 20 cobalt chromium brackets for 7 hours or 20 two-way titanium alloy stents for 4 hours. The minimum layer height of 10 microns allows printing durable parts with smooth surface finish. Two 200W lasers ensure fast and accurate printing. The intelligent software provides real-time monitoring of the printing process, a safety interlocking mechanism, and a self-diagnostics function.

Credit: xa-blt.com
Pros
- High print quality
- Fast print speed
- Intelligent software
- Build plate construction for fast loading
- Water-injection filter
Cons
- Build volume is quite small for large-scale manufacture
Dental 3D printing software
Almost all dental 3D printing solutions include proprietary software specially designed for dental practices and labs. It usually guides the user through all the stages starting with uploading a 3D scan to a CAD file with the following creation of a 3D digital model of the custom-tailored dental product. The slicer converts the CAD model to a printable file, usually STL, and prepares the model for printing. When the task is done, the software sends the print job to the printer.
Credit: uniz.com
The use of dedicated software recommended by the manufacturer provides maximum compatibility and ensures the best results without any downtimes.
Post-processing equipment
Printing with resins, which is the most popular material in digital dentistry, always implies several post-processing steps; that is why a lot of dental printers can be purchased as part of a complete solution, including, besides the printer itself, machines for washing and post-curing the printed parts.

Credit: anycubic.com
Is dental 3D printing expensive?
Compact dental resin 3D printers suitable for in-office printing can cost about a few thousand dollars, while industrial-grade large machines’ price can be as high as tens of thousands dollars and more. Such devices are good for dental labs with big production volumes as they allow for fast continuous printing thus providing the fast ROI.
Pros and cons of dental 3D printing
Pros
- Digital dentistry is capable of producing highly accurate dental appliances that can be easily customized at no additional cost.
- 3D printing saves a lot of time both for patients and practitioners.
- The cost per part is in many cases lower for 3D printed models compared to those produced by traditional methods.
- The dental technician’s work requires much more expertise than creation of digitally printed models.
- The process of dental 3D printing is usually highly automated.
- The final result in dental 3D printing is more predictable and reliable than in traditional dentistry.
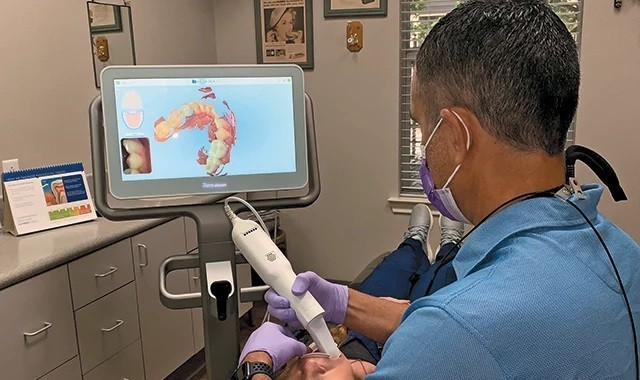
Credit: dentalproductsreport.com
Cons
-
The startup price is rather high.
-
Dental 3D printing requires special training (usually provided by the printer’s manufacturer).
-
Not all materials can be used for 3D printing (though the existing variety is already wide enough and growing constantly).
Bottom line
Dental 3D printing is one of the most rapidly growing additive manufacturing industries, and its popularity among both practitioners and patients is easily explained. Digital dentistry saves time and money, provides much higher quality of the printed dental appliances, and makes the treatment less painful and invasive for the patient and more convenient for the dentist.















Write a comment